Sentiment Analysis in R
What you will learn
- Understand what sentiment analysis is.
- Be able to perform sentiment analysis in R with the sentimentr package using real historical data.
Table of Contents
- 1. What is sentiment analysis?
- 2. How to get the data?
- 3. Performing sentiment analysis in R with sentimentr
- 4. Conclusions
In this lesson on sentiment analysis in R, you will learn how to perform sentiment analysis using the sentimentr package. To demonstrate the use of the package, you will compare the sentiment in the speeches of Adolf Hitler and Franklin Roosevelt about the declaration of war by Germany against the United States in 1941.
1. What is sentiment analysis?
Sentiment analysis or opinion mining consists of detecting the emotional tone of natural language. It works by assigning an emotion or emotional score to each word in a text. Some methods consider each word separately and others approach them in a wider context, for example, by evaluating their emotion considering its position in a sentence.
In this post we will be taking the latter approach, because the context of the word not rarely influences the emotion conveyed by it.
In this context, the sentimentr package is a great option for sentiment analysis in R, because it calculates the sentiment at the sentence level.
Each sentence is assigned a score that, in our example, varies from around -1.2 (very negative) to around 1.2 (very positive).
The sentimentr package takes into account valence shifters that can change the emotion of a sentence, for example:
- negator: I do not like it.
- amplifier: I really like it.
- de-amplifier: I hardly like it.
2. How to get the data?
We will gather the data for this example from two webpages using web scraping. If you want to learn more about web scraping, please consult ‘How to webscrape in R?’. The rvest package will be used to webscrape, specifically, the following three functions:
- read_html: Extracts the HTML source code associated with an URL;
- html_elements: Extracts the relevant HTML elements from the HTML code;
- html_text: Extracts the text (content) from the HTML elements;
The first step is to load the necessary packages and to save the URLs of the two speeches in variables.
Please follow the instructions of the sentimentr package webpage to install it.
content_copy Copy
library(rvest) # for webscraping
library(tidytext) # for cleaning text data
library(dplyr) # for data preparation
library(ggplot2) # for data viz
library(sentimentr) # for sentiment analysis in R
url_h <- "https://en.wikisource.org/wiki/Adolf_Hitler%27s_Declaration_of_War_against_the_United_States"
url_r <- "https://www.archives.gov/milestone-documents/president-franklin-roosevelts-annual-message-to-congress#transcript"If you inspect the source code of the webpages referenced above, you will realise that while the text from Wikipedia can be gathered by simply extracting the p elements,
for the speech from the American archives, we need to specify the particular div element where the speech is located. This is because the webpage contains an initial section with several paragraphs introducing President Roosevelt’s speech.
In the code below, note that Roosevelt’s speech requires an additional step to specify that the speech is within the div.col-sm-9 (a div with the class “col-sm-9”).
Also, note that we exclude the first text element of Hitler’s speech because it is actually metadata about the speech.
content_copy Copy
# Webscraping Hitler´s speech
speech_h <- read_html(url_h) %>%
html_elements("p") %>%
html_text()
# Webscraping Roosevelt´s speech
speech_r <- read_html(url_r) %>%
html_elements("div.col-sm-9") %>%
html_elements("p") %>%
html_text()
# Excluding first text element of Hitler's speech, because it is meta data
speech_h <- speech_h[2:155] 3. Performing sentiment analysis in R with sentimentr
Our next objective is to further split each of the paragraphs of our speeches into sentences. This can be achieved with the get_sentences function from the sentimentr package.
This function takes a character vetor, splits each element of this vector in sentences and delivers them in a list object. Each paragraph of our speeches becomes one list element that consists of a character vector containing the sentences of the respective paragraph.
content_copy Copy
sentences_h <- get_sentences(speech_h)
sentences_r <- get_sentences(speech_r)
Finally we can apply sentiment analysis to our sentences. We do that by using the sentiment function. It delivers a data frame containing:
- element_id: identifies the paragraph;
- sentence_id: identifies the sentence;
- word_count: informs how many words the sentence has;
- sentiment: informs the sentiment score attributed to that sentence;
In the code below we also check the most negative sentence in both speeches by ordering the data frames by sentiment (ascending) and getting the IDs of the sentences.
Note that to access a sentence in the list, you use the following syntax: list[[element_id]][sentence_id].
content_copy Copy
sentiment_h <- sentiment(sentences_h)
sentiment_r <- sentiment(sentences_r)
# Checking the most negative sentences (element n sentence id)
sentiment_h %>%
arrange(sentiment) %>%
head(1)
sentiment_r %>%
arrange(sentiment) %>%
head(1)
# Checking the most negative sentences (text)
sentences_h[[148]][1]
sentences_r[[39]][1]- Hitler’s most negative sentence: The government of the United States of America, having violated in the most flagrant manner and in ever increasing measure all rules of neutrality in favor of the adversaries of Germany, and having continually been guilty of the most severe provocations toward Germany ever since the outbreak of the European war, brought on by the British declaration of war against Germany on 3 September 1939, has finally resorted to open military acts of aggression.
- Roosevelt’s most negative sentence: I am not satisfied with the progress thus far made.
The next step is to visualize how the sentiment of both authors changed over the duration of the speech. For that, we will add two variables to the dataframe.
One to identify the author of the speech and the other to identify the order of the sentence in the speech (a sort of time variable). We also union the two data frames to make the plot coding with ggplot2 easier.
content_copy Copy
# adding a column to identify author and sentence order
sentiment_h$author <- "Adolf Hitler"
sentiment_h$sentence_n <- as.numeric(rownames(sentiment_h))
sentiment_r$author <- "Franklin Roosevelt"
sentiment_r$sentence_n <- as.numeric(rownames(sentiment_r))
# union of the two df
df_union <- rbind(sentiment_h, sentiment_r)To plot the sentiment using ggplot2, we assign the sentence order to the x axis, sentiment to the y axis and author to the color aesthetics. We then use geom_point to plot one point per sentence according to its sentiment and order in the speech.
We use geom_smooth to visualise the trend of the sentiment through the speech. Read more about geom_smooth here.
The scale_color_manual layer allows us to choose the colors attributed to each author. Feel free to choose your colors and ggplot2 theme.
To add the same ggplot2 theme as used in these plots, please check theme_coding_the_past(), our theme that is available here: ‘Climate data visualization with ggplot2’.
content_copy Copy
ggplot(data = df_union, aes(x = sentence_n,
y = sentiment,
color = author))+
geom_point(alpha = .4)+
scale_color_manual(name = "", values=c("#FF6885", "white"))+
geom_smooth(se=FALSE)+
xlab("Sentence Order")+
ylab("Sentiment")+
theme_coding_the_past()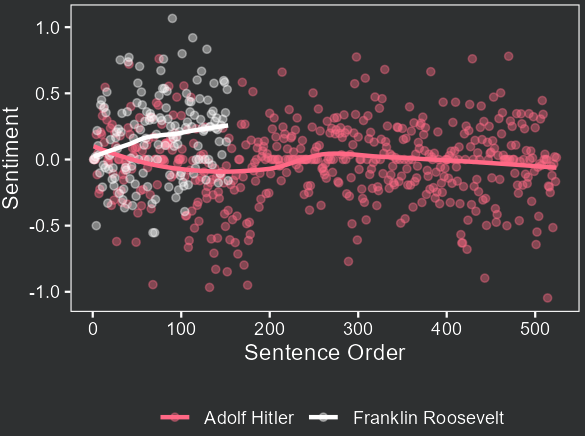
Note that the length of Roosevelt’s speech is shorter compared to Hitler’s. They both approach the declaration of war made by Germany against the US, but it is quite clear that the tone and emotions of Roosevelt are more positive. He starts low and increases the emotional tone until the end of the speech. The amplitude of Hitler’s emotions is a lot larger and, in general, the emotions are more negative.
In this case, sentiment analysis could be a powerful tool for a researcher to preselect which speeches to further analyze according to the emotional tone of interest. The method could also enrich a research comparing the speeches of more than two personalities and help to find personal styles and traces in the speeches of each personality. Finally, from a data science perspective, it would be interesting to know the differences in the results of sentiment analysis at the word level versus the analysis at the sentence level (as carried out in this post).
Feel free to leave your comment or question below and happy coding!
4. Conclusions
sentimentrpackage allows you to perform sentiment analysis in R, providing a powerful tool to estimate the emotional tone of sentences;- Sentiment analysis can be a powerful tool to preselect large amounts of texts and to find particular characteristics across different authors.
Comments
There are currently no comments on this article, be the first to add one below
Add a Comment
If you are looking for a response to your comment, either leave your email address or check back on this page periodically.